Adaboost Algorithm
#Computers
A boosting algorithm that minimizes 0-1 Loss
$\displaystyle \epsilon_{t}=\sum_{n}w_{t}(n)\mathbb{1}(y_{n}\neq h_{t}(x_{n}))$
- Error (0-1 loss specifically) for the weight given to $\displaystyle h_{t}(\cdot )$, the weak (i.e. base) classifier for this epoch $\displaystyle t$ in the training cycle
- $\displaystyle n$ corresponds to a particular training example
- $\displaystyle w_{t}(n)$ is the weight for this epoch $\displaystyle t$ for a particular sample $\displaystyle n$
- Set to $\displaystyle \frac{1}{n}$ for $\displaystyle t=1$
$\displaystyle \beta_{t}=\frac{1}{2}\ln\left( \frac{1-\epsilon_{t}}{\epsilon_{t}} \right)$
- Contribution of $\displaystyle h_{t}$ to final classifier
- $\displaystyle -\infty$ for large $\displaystyle \epsilon_{t}$
- However, negative values for $\displaystyle \beta_{t}$ are always made positive by flipping the value of the weak classifier
- $\displaystyle 0$ for $\displaystyle \epsilon_{t}=\frac{1}{2}$, or when guessing randomly
- $\displaystyle 1$ for $\displaystyle \epsilon_{t}=\frac{1}{3}$
- $\displaystyle \infty$ for 0 $\displaystyle \epsilon _t$
$\displaystyle w_{t+1}(n)\propto w_{t}(n)e^{-\beta_{t}y_{n}h_{t}(x_{n})}$
- Updated weights. We compute this step $\displaystyle T$ times, or the number of epochs we'd like until we've minimized error
$\displaystyle h[x]=\text{sign}\left[ \sum_{t = 1}^{T}\beta_{t}h_{t}(x) \right]$
- Final classifier
Exponential Loss Minimization
$\displaystyle a_{t}(x)=a_{t-1}(x)+\beta_{t}h_{t}(x)$
- The Adaboost classifier for the current epoch equals the previous Adaboost classifier plus the current weighted base classifier
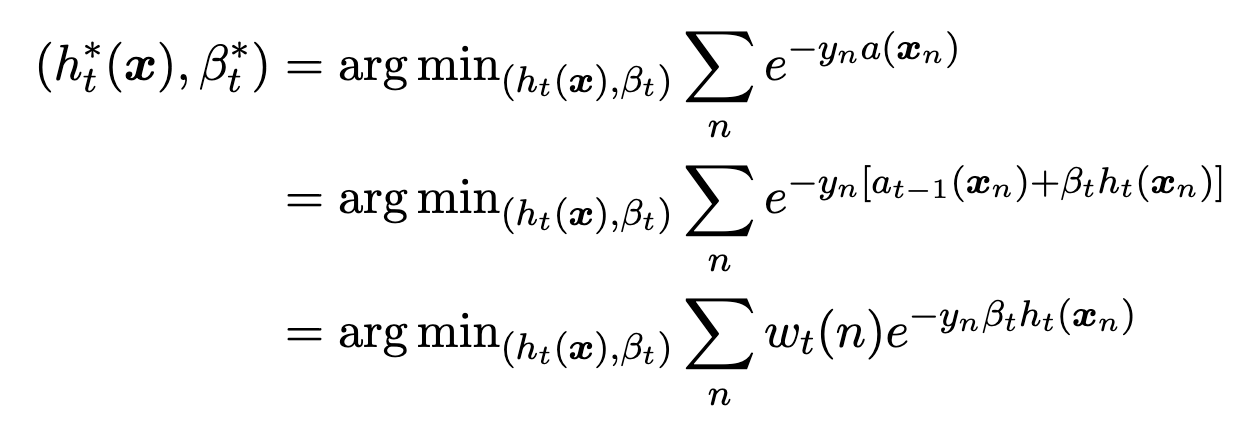
- Adaboost minimizes empirical risk of exponential loss
$\displaystyle w_{t}(n)=e^{-y_{n}a_{t-1}(x)}$
- The weight of the exponential loss of a particular weak classifier is the exponential loss of our previous Adaboost classifier
- $\displaystyle a_{t-1}(x)$ is the Adaboost classifier for epoch $\displaystyle t-1$
Training
- AdaboostTrain():
- For each of $\displaystyle d$ features, sort data points for that feature value
- This is the pre-sorting step and contributes $\displaystyle O(dN\log N)$ to the runtime
- for $\displaystyle t$ in $\displaystyle T$:
- $\displaystyle h_{t}(x):=$ decision stump threshold that minimizes error
- Can be found in $\displaystyle O(dN)$ time by going for each of $\displaystyle d$ features, starting with the smallest threshold, calculating error, moving the threshold to the next datapoint as determined by our pre-sorting, updating the error in $\displaystyle O(1)$ time, and so on until we find the threshold that had the smallest error
- $\displaystyle \epsilon_{t}:=\sum_{n}w_{t}(n)\mathbb{1}(y_{n}\neq h_{t}(x_{n}))$
- $\displaystyle \beta_{t}:=\frac{1}{2}\ln\left( \frac{1-\epsilon_{t}}{\epsilon_{t}} \right)$
- $\displaystyle w_{t+1}(n):=w_{t}(n)e^{-\beta_{t}y_{n}h_{t}(x_{n})}$
- $\displaystyle h_{t}(x):=$ decision stump threshold that minimizes error
- For each of $\displaystyle d$ features, sort data points for that feature value
- $\displaystyle h[x]=\text{sign}\left[ \sum_{t = 1}^{T}\beta_{t}h_{t}(x) \right]$
$\displaystyle O(dN\log N+dNT)$
- Training runtime using decision stumps as the base classifier