Decision Tree
#Computers
Animation Video
In a feature space, it will ask questions (e.g. is the data point below $\displaystyle x_{0}$ along the $\displaystyle x$ axis) that most minimize the information entropy or the Gini Index. This could mean making a split such that only labeled data points of one group are one side
$\displaystyle \Delta H=H_{\text{parent}}-\sum_{i}p_{i}H_{\text{children}}$
- The information entropy change between parent and child for a decision tree node split
- $\displaystyle H$ may be replaced by $\displaystyle g$, the Gini Index
- The goal is generally to maximize entropy reduction/minimize entropy/maximize information gained per split/minimize $\displaystyle \Delta H$/maximize the gain in $\displaystyle g$
- $\displaystyle H_{\text{parent} }$ is the information entropy of the parent information before the split
- $\displaystyle p_{i}$ is the probability of being in one branch of the decision tree
- $\displaystyle H_{\text{children}}$ is the information entropy achieved by one branch
Classification
The model is trained so as to achieve either pure leaf nodes (among the training data, only pure classes are obtained) or after a certain threshold (limit the number of decision nodes)
Sometimes better than a linear classifier
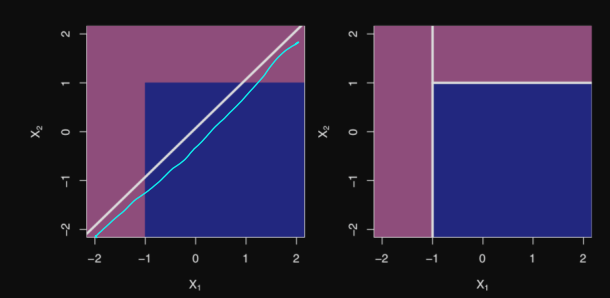
Sometimes worse than a linear classifier
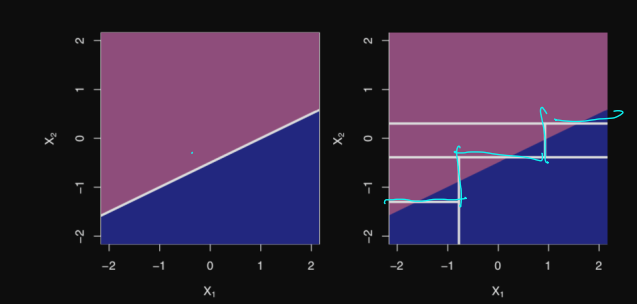
Regression
Takes the average value of those within the decision tree zone
Testing Algorithm
To classify after training, the algorithm will for each split in the tree, use the features of a data point to decide what path to go down before eventually finding a leaf or zone that will dictate the label
- DecisionTreePredict(tree, instance)
- if tree has form LEAF(target):
- return target
- elif tree has form NODE(feature, LEFT, RIGHT)
- if feature = NO in instance
- return DecisionTreePredict(LEFT, instance)
- return DecisionTreePredict(RIGHT, instance)
- if feature = NO in instance
- if tree has form LEAF(target):
Training Algorithm
Building the decision tree
Binary Classification
- DecisionTreeData(data, features)
- guess := most frequent label in data
- If all labels in data are equivalent or features is empty
- return LEAF(guess)
- f := "best" feature (determinable by ID3 algorithm for instance) that splits the nodes
- NO := subset of data with label no
- YES := subset data with label yes
- return NODE(DecisionTreeData(NO, features - f), DecisionTreeData(YES, features - f))
Here, we define NODE() to be as NODE(left, right)
$\displaystyle O(dn\log n)$
- $\displaystyle d$ is the max depth of the tree?
- $\displaystyle n$ is the number of data points in the training data
Best Feature Selection
- Random
- Highest-accuracy
- ?
- Max-gain
ID3 (Iterative Dichotomiser 3) Algorithm
Called this because it dichotomizes iteratively