Feed Forward
#Math #Computers
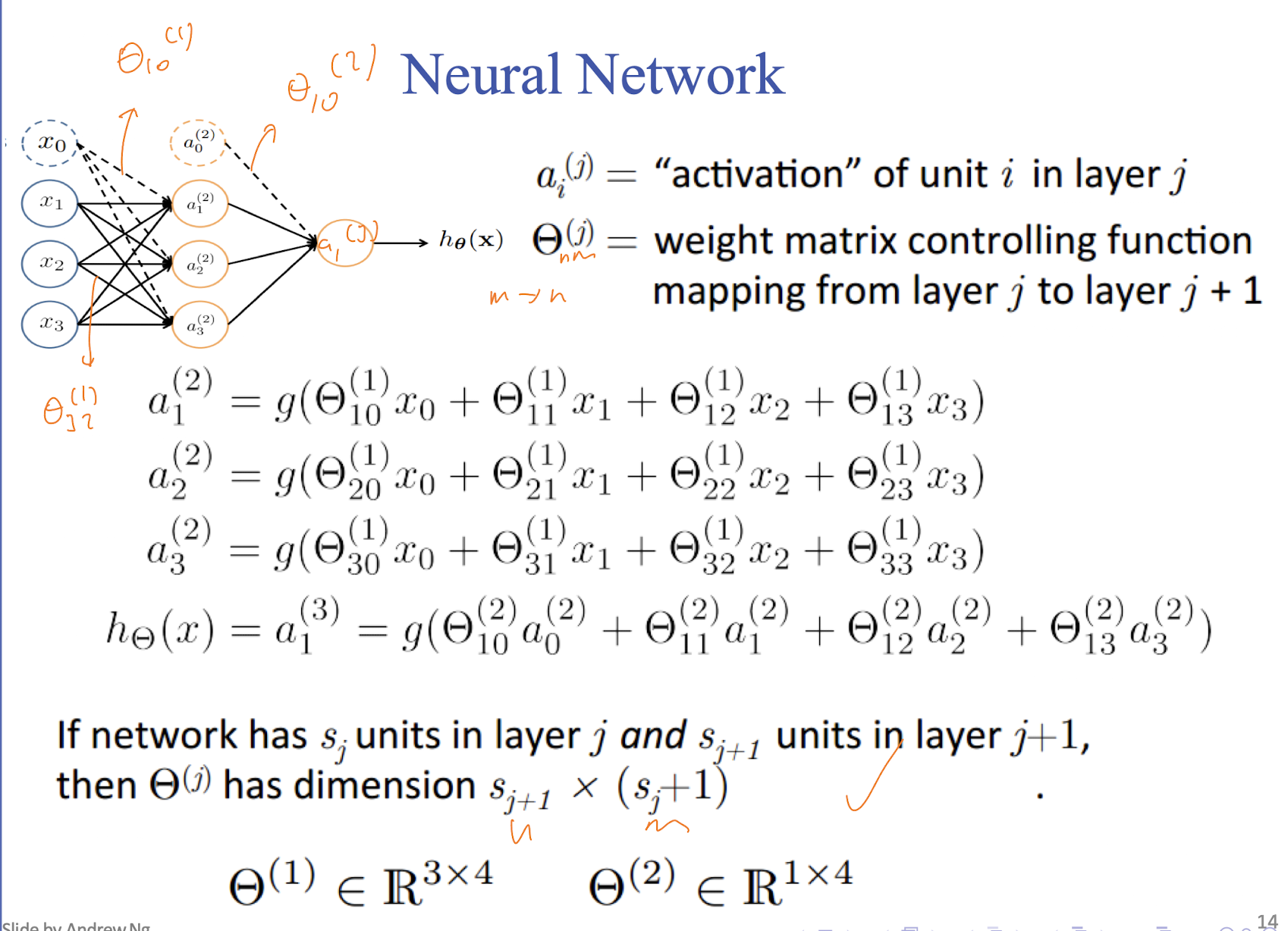
$\displaystyle a_{0}$ is a bias term
$\displaystyle \boldsymbol{a}^{(i+1)}=\sigma(\boldsymbol{\Theta^{(i)} a^{(i)}})$
- $\displaystyle \boldsymbol{a}^{(i)}$ is the activation of the $\displaystyle i$th layer of the neural network and is the same as: $$
\begin{pmatrix}
a_{0}^{(i)} \\ \vdots \\ a_{n_{i}}^{(i)}
\end{pmatrix}
$$ - Where $\displaystyle n_{i}$ is the number of nodes in the $\displaystyle i$th layer
- $\displaystyle \sigma(\cdot )$ is the sigmoid function and is applied to each entry of the vector
- $\displaystyle \boldsymbol{\Theta}^{(i)}$ is the weight matrix going from the $\displaystyle i$th layer to the $\displaystyle (i+1)$th layer (can also be represented as $\displaystyle \boldsymbol{W}$)
- The above example can be thought of as $\displaystyle \boldsymbol{a}^{(2)}=g(\Theta^{(2)}a^{(1)})$