A boosting algorithm that minimizes 0-1 Loss
- Error (0-1 loss specifically) for the weight given to , the weak (i.e. base) classifier for this epoch in the training cycle
- corresponds to a particular training example
- is the weight for this epoch for a particular sample
- Set to for
- Contribution of to final classifier
- for large
- However, negative values for are always made positive by flipping the value of the weak classifier
- for , or when guessing randomly
- for
- for 0
- Updated weights. We compute this step times, or the number of epochs we’d like until we’ve minimized error
- Final classifier
Exponential Loss Minimization
- The Adaboost classifier for the current epoch equals the previous Adaboost classifier plus the current weighted base classifier
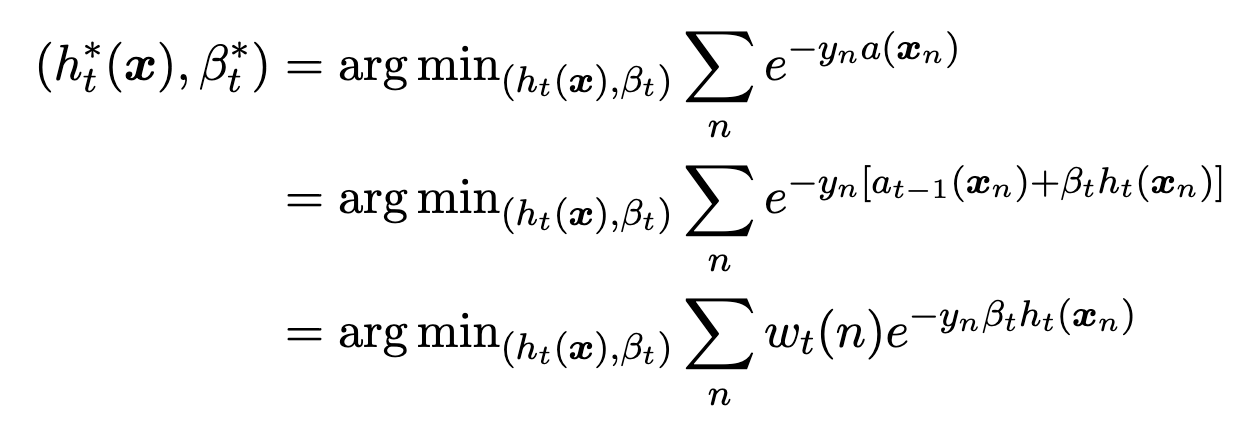
- Adaboost minimizes empirical risk of exponential loss
- The weight of the exponential loss of a particular weak classifier is the exponential loss of our previous Adaboost classifier
- is the Adaboost classifier for epoch
Training
- AdaboostTrain():
- For each of features, sort data points for that feature value
- This is the pre-sorting step and contributes to the runtime
- for in :
- decision stump threshold that minimizes error
- Can be found in time by going for each of features, starting with the smallest threshold, calculating error, moving the threshold to the next datapoint as determined by our pre-sorting, updating the error in time, and so on until we find the threshold that had the smallest error
- decision stump threshold that minimizes error
- For each of features, sort data points for that feature value
- Training runtime using decision stumps as the base classifier